在面试时,我常问候选人老生常谈的一个问题便是「聊聊你对闭包的理解,闭包是如何存储变量的?又是如何回收的?」
百分之90的候选人,都是回答:”函数内部可以访问外部的变量,就形成了闭包”,当然我不能说候选人这种说法一定是错的,只是太字面了。于是,我继续追问,可以再具体一点吗?为什么内部可以访问外部的变量就形成了闭包,它是怎么存储并回收的呢?这时候,候选人就回答不上来了。
如果对闭包理解深一点的同学可能会这么回答:
「在 JavaScript中,根据词法作用域的规则,内部函数总是可以访问其外部函数中声明的变量,当通过调用一个外部函数返回一个内部函数后,即使该外部函数已经执行结束了,但是内部函数引用外部函数的变量依然保存在内存中,我们就把这些变量的集合称为闭包」这个回答还算标准一些,至少他了解闭包中的函数什么时候会执行结束,知道变量会被存在内存中。
其实,想要回答好闭包这个问题。那么理解作用域链是理解闭包的基础,但理解作用域链又需要了解 调用栈、执行上下文、词法环境、变量环境。
变量是通过作用域链来查找的,变量的作用域是由词法决定的,也就是说作用域是在你写代码的时候就已经决定了的(取决于代码的位置)。那么什么是词法作用域呢?
💡 词法作用域就是指作用域是由代码中函数声明的位置来决定的,所以词法作用域是静态的作用域,通过它就能够预测代码在执行过程中如何查找标识符。
💡 词法作用域是代码编译阶段就决定好的 和函数是怎么调用的没有关系。JavaScript 语言的作用域链是由词法作用域决定的,而词法作用域是由代码结构来确定的。
引用《你不知道的js》中的定义:
闭包是基于词法作用域书写代码时所产生的自然结果。当函数可以记住并访问所在的词法作用域时,就产生了闭包,即使函数是在当前词法作用域之外执行。
那么 闭包是如何回收的:
通常,如果引用闭包的函数是一个全局变量,那么闭包会一直存在直到页面关闭;但如果这个闭包以后不再使用的话,就会造成内存泄漏。如果引用闭包的函数是个局部变量,等函数销毁后,在下次 JavaScript 引擎执行垃圾回收时,判断闭包这块内容如果已经不再被使用了,那么 JavaScript 引擎的垃圾回收器就会回收这块内存。
使用必要需要注意的原则:
💡 如果该闭包会一直使用,那么他可以作为全局变量而存在;但如果使用率不高,而且占用内存又比较大的话,那就让他成为一个局部变量
上面我们简单总结了闭包的大概流程,下面就从堆栈空间的角度在深入分析闭包的形成及调用过程.
在理解这个概念之前,首先我们要知道 “内存空间”,JS的内存模型包含三种类型的内存空间,分别是:
- 代码空间(主要用来存储可执行代码的)
- 堆空间(主要用来存储对象类型)
- 缺点:分配内存和回收内存会占用一定的时间
- 栈空间(其实就是调用栈,用来存储执行上下文的,主要存放一些原始类型的小数据)
对象类型是存放在堆空间的,在栈空间只是保留了对象的引用地址,当JS需要访问数据的时候,是通过栈中的引用地址来访问的(这块是不是想起了基本类型和引用类型的区别)
所以,你可以理解成,原始类型的数据值都是用来直接保存"栈"中的, 引用类型的值是存放在"堆"中的
说了这么多很干的概念,为了带你回顾上面的概念,不只是停留在闭包概念的理解,这里引入代码进行解读:
function foo() {
var myName = "李小宝"
let test1 = 1
const test2 = 2
var innerBar = {
setName:function(newName){
myName = newName
},
getName:function(){
console.log(test1)
return myName
}
}
return innerBar
}
var bar = foo()
bar.setName("李大宝")
bar.getName()
console.log(bar.getName())
分析阶段:
由于变量 myName、test1、test2 都是原始类型数据,所以在执行foo函数的时候,它们会被压入到调用栈中;当foo函数执行结束之后,调用栈中foo函数的执行上下文会被销毁,但是因为foo函数产生了闭包,所以变量myName和test1并没有被销毁,而是保存在内存中。
为什么会保存在内存中?「首先要站在内存模型的角度分析代码的执行流程」
- 当 JavaScript 引擎执行到 foo 函数时,首先会编译,并创建一个空执行上下文。
- 在编译过程中,遇到内部函数 setName,JavaScript 引擎还要对内部函数做一次快速的词法扫描,发现该内部函数引用了 foo 函数中的 myName 变量,由于是内部函数引用了外部函数的变量,所以 JavaScript 引擎判断这是一个闭包,于是在堆空间创建了一个“closure(foo)”的对象(这是一个内部对象,JavaScript 是无法访问的),用来保存 myName 变量。
- 接着继续扫描到 getName 方法时,发现该函数内部还引用变量 test1,于是 JavaScript 引擎又将 test1 添加到“closure(foo)”对象中。这时候堆中的“closure(foo)”对象中就包含了 myName 和 test1 两个变量了。
- 由于 test2 并没有被内部函数引用,所以 test2 依然保存在调用栈中。
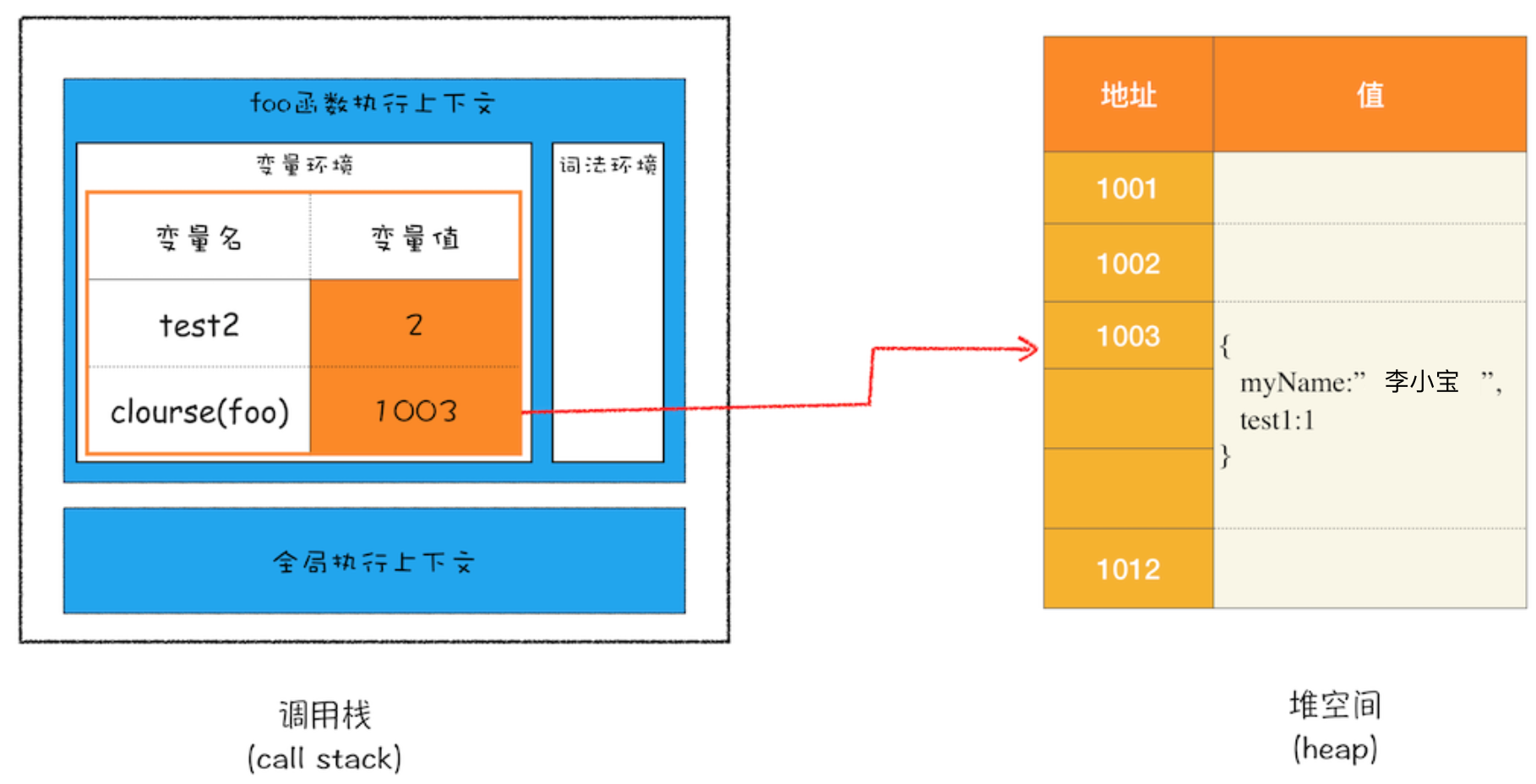
从上图你可以清晰地看出,当执行到 foo 函数时,闭包就产生了;当 foo 函数执行结束之后,返回的 getName 和 setName 方法都引用“clourse(foo)”对象,所以即使 foo 函数退出了,“clourse(foo)”依然被其内部的 getName 和 setName 方法引用。所以在下次调用bar.setName或者bar.getName时,创建的执行上下文中就包含了“clourse(foo)”
结论:产生闭包的核心有两步:
第一步是需要预扫描内部函数;第二步是把内部函数引用的外部变量保存到堆中。
现在我们通过上面的例子,已经了解了闭包的产生及存储过程。下面,我为你准备了一个更简单的例子,直接对着这个来回答闭包的问题,话不多说,上代码:
// 举一个简单的例子进行说明:
function A() {
var a = '我是小a';
let b = "我是小b"
var B = function() {
console.log(a)
}
return B()
}
A()
引用上面的概念:
在JavaScript中,根据词法作用域的规则,内部函数总是可以访问其外部函数中声明的变量,当通过调用一个外部函数返回一个内部函数后,即使该外部函数已经执行结束了,但是内部函数引用外部函数的变量依然保存在内存中,我们就把这些变量的集合称为闭包。
简单理解就是:
A函数中有个B函数,B函数可以访问A函数中的变量,此时就把A函数中的变量的集合称为闭包。由于A函数中的变量a是原始类型数据,所以在执行A函数的时候,它会被压入到调用栈中;当A函数执行结束之后,调用栈中A函数的执行上下文会被销毁,但是因为A函数产生了闭包,所以变量a并没有被销毁,而是保存在内存中。
变量a之所以会被保存在内存中:
主要是因为在编译代码的过程中,遇到内部函数B的时候,JS引擎对内部函数要做一次快速的词法扫描 ,如果发现该内部函数引用了A函数中的a变量,JS引擎判断出这个一个闭包,就在堆空间创建了一个"closure(A)" 的对象(这是一个内部对象,JS是无法访问的),这个对象用来保存a变量。如果还有其它的变量,也依次将其添加到这个"closure(A)" 对象中。由于变量b并没有被内部函数引用,所以b依然保存在调用栈中。
为什么函数B函数执行退出后,为什么A函数中的a还被引用?
这是因为B函数退出后,”closure(A)”依然被其内部的B函数引用。所以在下次调用A函数的时候,创建的执行上下文中就包含了”closure(A)”
内存是如何泄漏的?如何避免写代码的时候产生内存泄漏?
1.函数A声明的变量a在函数B被执行成功退出之后,依然保留对a的引用,没有及时卸载掉,内存依然还在,就产生了内存泄漏。
2.及时清除未使用过的变量 如:a = null; 或者尽量避免在内部作用域内声明函数对外部的引用。
以上就是对闭包原理的解读以及如何更好的回答面试官 关于闭包的这个问题的阐述,相信你下一次再被面试官问到这个问题的时候,能从上面的角度去回答,那会给面试官一个很大的惊喜。