HTTP(Hyper Text Transfer Protocol-超文本传输协议)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。
HTTP1.0
规定浏览器和服务器保持短暂的连接,浏览器的每次请求都需要与服务器建立一个 TCP 连接,服务器处理完成后立即断开 TCP 连接。
HTTP1.0 缺点
- 无法复用连接,每次发送请求,都需要进行一次 TCP 连接,而 TCP 的连接释放过程又是比较费事的。这种无连接的特性会使得网络的利用率变低。
- 一次只能连接一个请求,请求响应完毕,才能响应下一个请求
- 不支持断点续传,也就是说,每次都会传送全部的页面和数据(一旦中途中断,必须重新开始上传)
HTTP1.1
HTTP1.1 继承了 HTTP1.0 的 TCP 连接,对其存在的一些问题做了更多的改善
持久连接(keep-alive)也称 “长连接”
保持 HTTP 连接不断开,避免了每次客户端与服务器请求都要重复建立释放建立 TCP 连接,提高了网络的利用率。如果客户端想关闭 HTTP 连接,可以在请求头中携带 Connection: false 来告知服务器关闭请求。
http1.1中浏览器客户端在同一时间,针对同一域名下的请求有一定数量的限制,超过此数量请求会被阻塞问题:为什么HTTP1.x版本要限制并发请求数?
个人理解:计算机资源是有限的,每一个 tcp 连接都会占用资源,且有线程(libuv)切换成本,不可能无限制的创建tcp连接- 占用资源:端口是有限的(每个tcp都会限制一个端口)、内核内存、文件描述符、内核文件打开数、数据接收/缓冲区、线程 - 对服务端和客户端来说,tcp连接都是很贵的 - H1.0之后,引入 **keep-alive** 就是为了复用tcp连接(这里的引用不是说H1.0之后才出现,其实H1.0已经有了 keep-alive 只是默认不开启),因为大多数情况下,复用已有连接会比创建(三次握手耗时)一个新的链接性能高很多 - 服务端需要防御ddos攻击,所以会限制同一个ip过来的连接数
HTTP 管道化
- 多个请求可以同时发送,但是服务器还是按照顺序进行回应(abcd ⇒ abcd 一旦 a 被阻塞,后面的请求都要排队等着,其实就是队列【先进先出】的思想)这就造成了队头阻塞的问题
分块编码传输
新增 Host 头处理
更多缓存处理
- H1.0 主要使用 header 里的 If-Modified-Since,Expires 来做为缓存判断的标准
- H1.1 Etag、If-None-Match、cache-control 等更多可供选择的缓存头来控制缓存策略(可参考之前写的强缓存和协商缓存文章聊聊浏览器的缓存策略)
新增更多状态码
- 新增了 24 个错误状态响应码,如 409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
断点续传、并行下载
- 通过使用请求头中的 Range 来实现
HTTP1.1 缺点
- 队头阻塞(Head-of-line blocking)
- 当单个(慢)对象阻止后续对象前进时,即队头阻塞。类比队列,先进先出,一旦有一个阻塞了后续的都会受到影响
- 头部冗余
- TCP 连接数限制
- 一个 TCP 连接最多只能派发固定的请求数量(chrome 是 6 个)
- TCP 慢启动
- TCP 慢启动是 TCP 拥塞控制的一种策略。TCP 在刚建立连接完成后,首先是有个慢启动的过程,这个慢启动的意思就是一点一点的提高发送数据包的数量。当发送方每收到一个 确认包,拥塞窗口的大小就会加 1。说慢启动会带来性能问题就是因为如果请求一个不大的页面关键资源也要经过这样的慢启动过程,那么页面的渲染性能就会大大的降低。
- 解决:
- 慢开始,拥塞避免
- 快重传,快恢复
HTTP2.0
HTTP2.0 在 HTTP1.1 的基础上,对其存在的一些问题做了更多的改善
强制开启 TLS
- TCP + TLS(SSL)
二进制分帧
- 原本是一整块信息一次性下发,http1.0 是基于文本格式,分帧后先在
发送方拆分成更小的包,并以二进制的方式进行编码传输,然后在接受方重组 - 串行通讯 ⇒ 多路复用(关于此点,其实还可以聊聊
H1.1的管道通讯机制)- 管道通讯:多个请求同时发送给服务端(缺点会按照发送顺序来返回对应的请求数据)
- HTTP2 会将所有传输的信息分割为更小的消息和帧(frame)并对它们采用二进制格式的编码,这种负责拆分、组装请求和二进制帧的一层就叫做二进制分帧
- 拆解成多个包异地恢复
- 数据给到下层协议之前将数据“打散”成更小的帧,并以 2 进制方式进行编码传输
- 原本是一整块信息一次性下发,http1.0 是基于文本格式,分帧后先在
多路复用
HTTP1.1 如果要同时发起多个请求,就得建立多个 TCP 连接,因为一个 TCP 连接同时只能处理一个请求,在 HTTP2 上,多个请求可以共用一个 TCP 连接,这称为“多路复用”。同一个请求和响应用一个流来表示,并有唯一的流 ID 来标识。多个请求和响应在 TCP 连接中可以乱序发送,到达目的地后再通过流 ID 重新组建。
HTTP/1.1 协议的请求-响应模型大家都是熟悉的,我们用“HTTP 消息”来表示一个请求-响应的过程,那么 HTTP/1.1 中的消息是“管道串形化”的:只有等一个消息完成之后,才能进行下一条消息;而 HTTP/2 中多个消息交织在了一起,这无疑提高了“通信”的效率。这就是多路复用:在一个 HTTP 的连接上,多路“HTTP 消息”同时工作。(具体见下图)
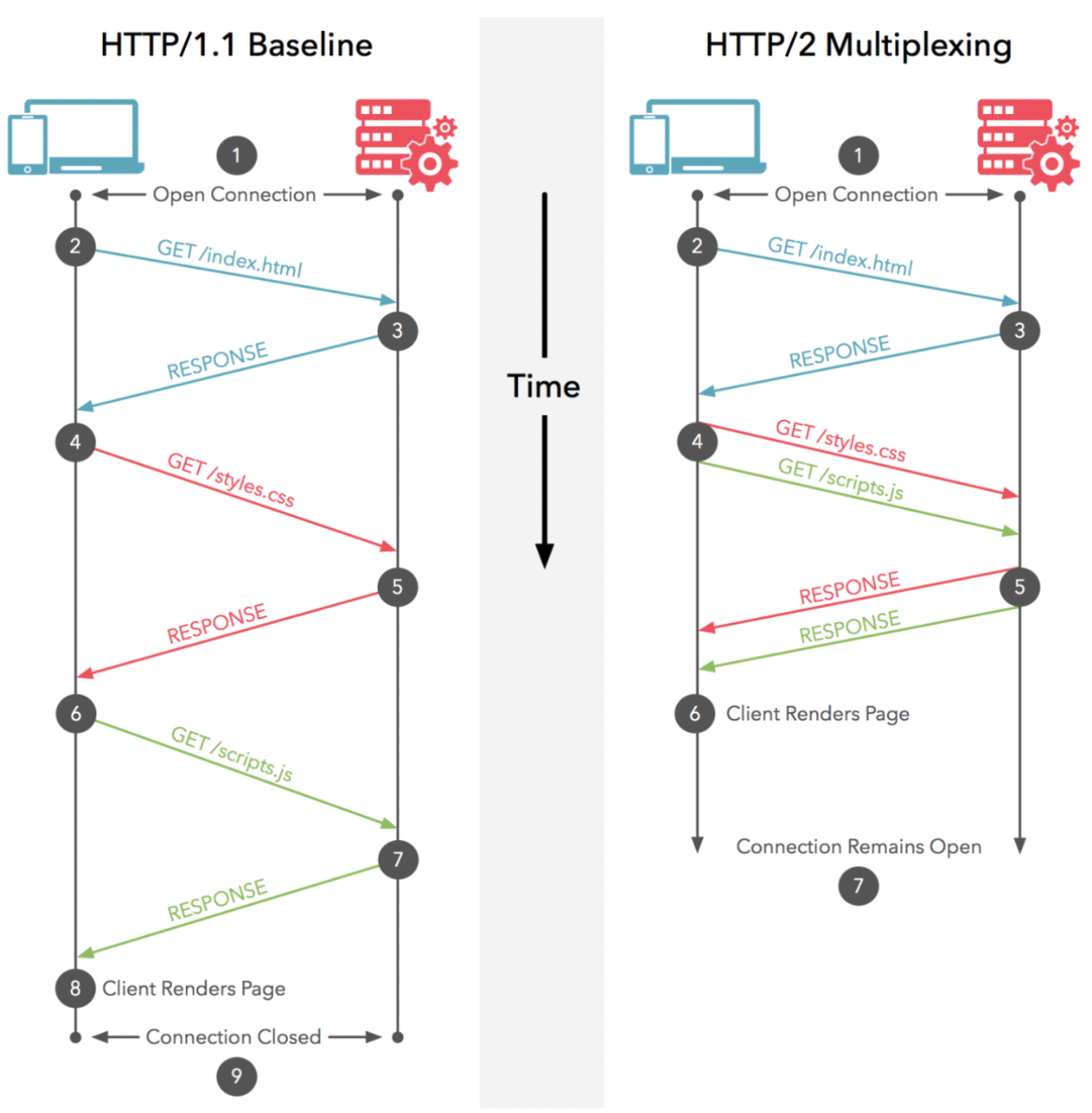
多路复用-202208152104655.png 为什么 http1.1 不能使用【多路复用】呢?因为 HTTP/2 是基于二进制“帧”的协议,HTTP/1.1 是基于“文本分割”解析的协议。
头部压缩
减少头部需要传输的信息量,每次请求都会重复的发送对用的 request header(几 k-几百 k)会消耗更多的资源。所以 H2.0 采用了
hpack算法(原理:用 header 字段表里的索引代替实际的 header)进行头部压缩,具体做法就是:通讯双方持有一份字典(静态(content-type method ⇒ 直接发索引)表/动态表),对于表内的字段(值),直接发放索引。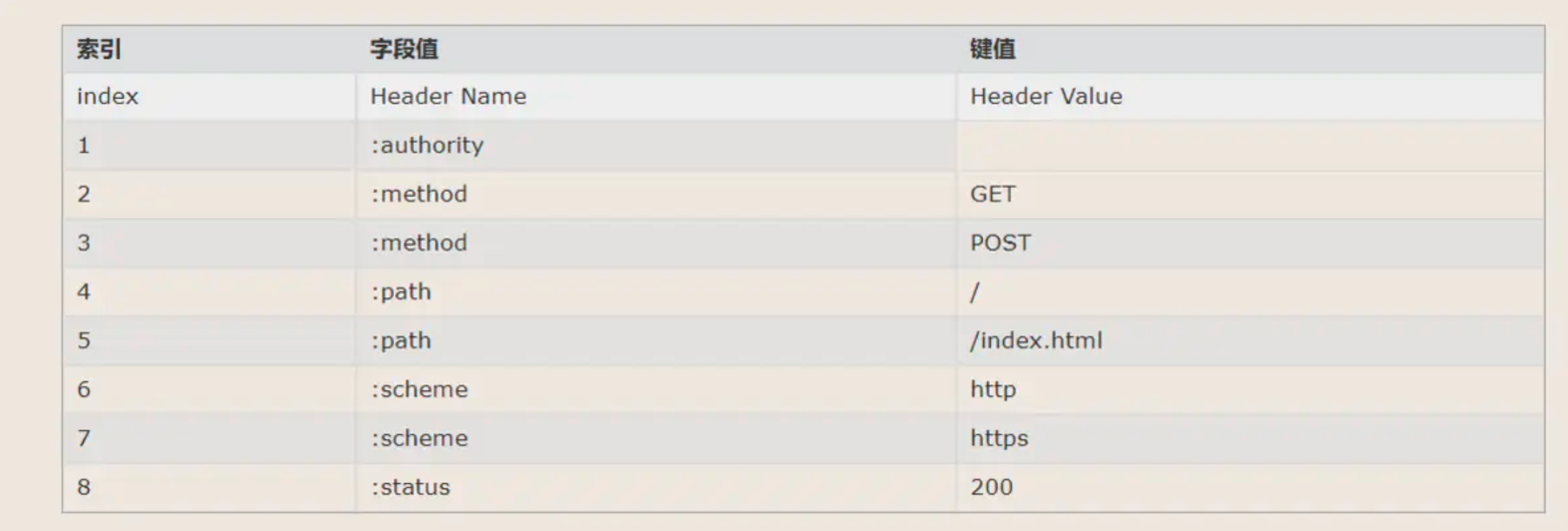
header字段表-202208152106677.png 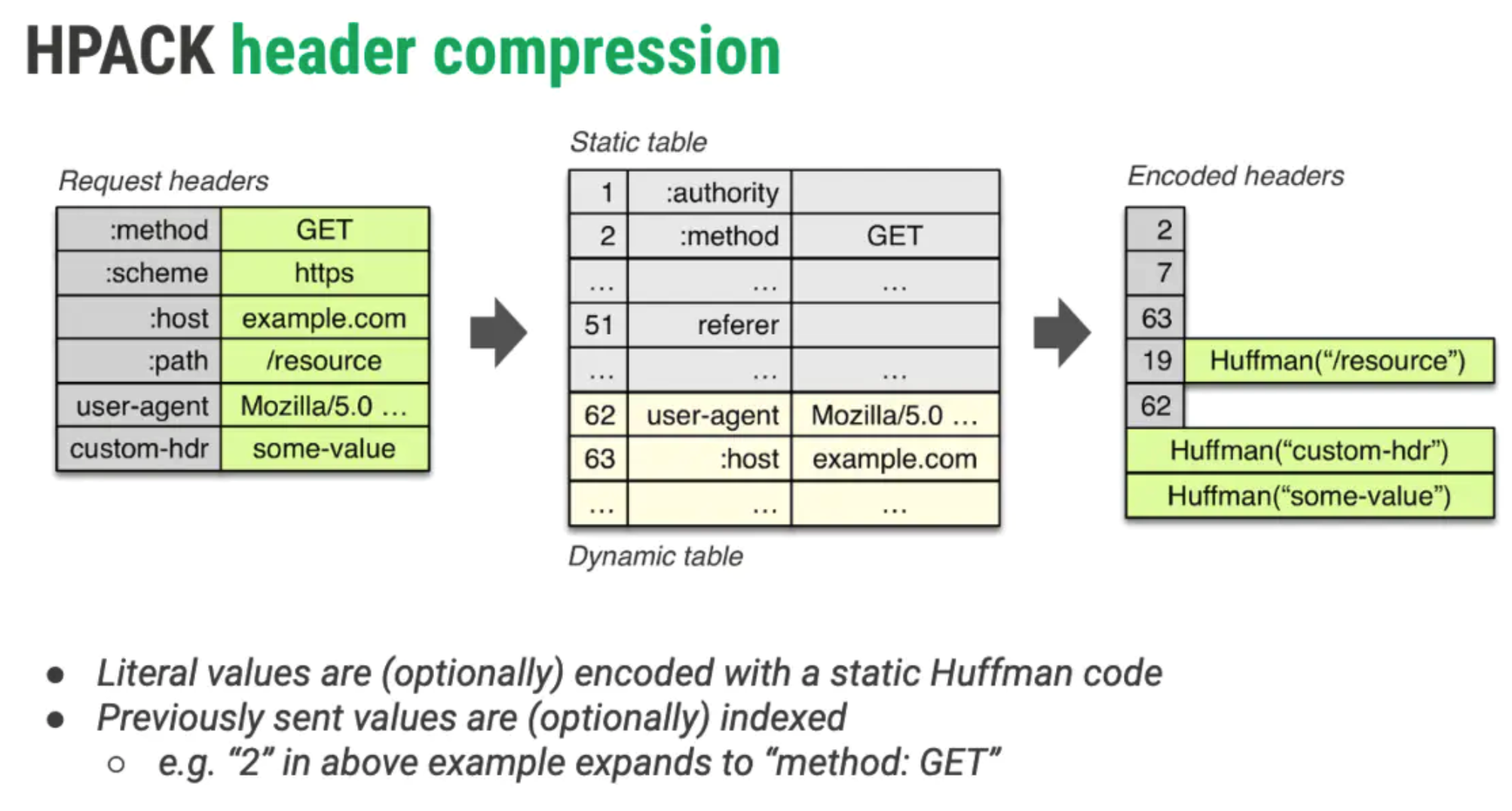
hpack-header-compression-202208152106383.png
服务端推送
- 主动下发关键资源
HTTP2 带来的变化
原本依赖多个 tcp 连接,现在都集中在同一个连接上(多个请求可以共有一个 TCP 连接),网络效率高了很多,但可能会造成性能瓶颈
一些性能优化手段已经失效了,例如:
- 雪碧图之类的资源合并 - 发起请求成本降低
- 资源内嵌 - 通过
server push主动下发
但有一些依然有效
- 压缩(Nginx 开启 gzip 压缩)
# 开启gzip 压缩 gzip on; # 设置gzip所需的http协议最低版本 (HTTP/1.1, HTTP/1.0) gzip_http_version 1.1; # 设置压缩级别,压缩级别越高压缩时间越长 (1-9) gzip_comp_level 4; # 设置压缩的最小字节数, 页面Content-Length获取 gzip_min_length 1000; # 设置压缩文件的类型 (text/html) gzip_types text/plain application/javascript text/css;- CDN(内容分发网络)
CDN 服务提供商将源站的资源缓存到全国各地的高性能加速节点。当用户访问相应的服务资源时,会将用户调度到最近的节点,并将最近的节点 IP 返回给用户,使用户就近获取所需内容,从而可以更快、更稳定地传输内容。CDN 的核心点有两个,一个是缓存,一个是回源:- 缓存: 将源服务器请求来的资源按要求缓存。
- 回源:CDN 节点没有响应到应该缓存的资源(没有缓存过或者是缓存已经到期),就会回源站去获取
- 缓存 等等
HTTP2 存在的问题
- HTTP2 虽然在请求的通信上带来了很大的性能提升,但所有的请求都是基于一个 TCP 之上的,一旦请求的数量过多,就会带来一定的性能瓶颈。
- TCP 层面的
队首阻塞(abcd ⇒ b 出错了 ⇒ cd 也会被阻塞) 但在HTTP/2 中一个域名又只使用一个 TCP 连接,一个一个请求是跑在一个 TCP 长连接中的,如果其中一个数据流出现了丢包的情况,那么就会阻塞该 TCP 连接中的所有请求,进而影响了HTTP/2 的传输效率。 - 所以再此基础之上有了 HTTP3.0 的提议。
HTTP3.0 展望
HTTP/3和HTTP/2主要区别在于 HTTP/3 基于 QUIC 作为传输层来处理流,而 HTTP/2 使用 TCP 来处理 HTTP 层中的流。
可以把 QUIC 看成是集成了“TCP+HTTP/2 的多路复用 +TLS ”的一套协议。其中的快速握手功能(基于UDP)实现了使用 0-RTT 或者 1-RTT 来建立连接,可以大大提升首次打开页面的速度。
- H3 解决方法 ⇒ TCP ⇒ UDP
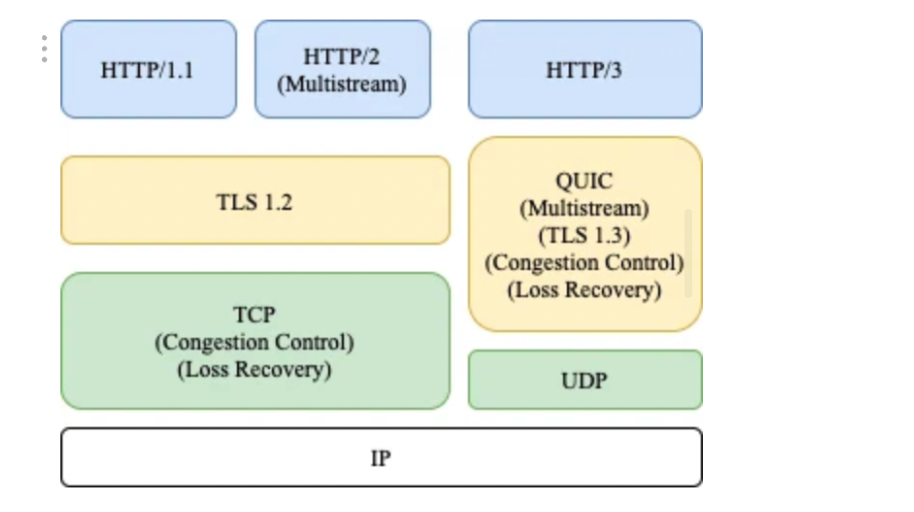
- H2 基于 TCP,HTTP3 直接基于 UDP ⇒ QUIC(quick udp internet connection)
- QUIC 是基于 UDP 实现的;丢包回复、拥塞控制、加解密(TLS1.3)、多路复用逻辑
- 优势
- 启动性能:无需 TCP 三次握手;
- TLS 建联之前发送请求 ⇒ 3RTT(
Round-Trip-Time 往返时间) ⇒ 0/1 RTT
- 解决 TCP 队首阻塞
- 缺点
- 兼容性差
- 用户态 ⇒ 性能问题
- 优势
参考: